

Остаться без работы из-за «расистского» ПО
В октябре 2021 года ошибка системы идентификации, которую использует компания Uber в Великобритании, оставила темнокожего водителя без средств к существованию. Проработав в компании пять лет, однажды он не смог войти в свой профиль, чтобы начать развозить людей, — система просто перестала распознавать его. Водитель посчитал, что всему виной «расистское» программное обеспечение, которое некорректно работает при идентификации цветных людей.
Фото: Paul Barron / Shutterstock
С помощью приложения Uber пытается исключить из рядов водителей нелегалов и водителей без лицензии. Отстаивать свои права оставшийся без работы мужчина пошёл в комиссию по трудовым спорам, а его позицию поддержал Независимый профсоюз работников Великобритании (IWGB). Там заявили, что с начала пандемии как минимум 35 других водителей попали в похожую ситуацию из-за ошибок в программном обеспечении Uber. Они призвали компанию отказаться от «расистского» алгоритма и восстановить уволенных водителей.
…И как она ошибается
Столкнуться с реальностью, в которой искусственный интеллект далек от идеала, научному сообществу пришлось уже через два года. В 2013 году исследователь Google Кристиан Сегеди и его коллеги опубликовали препринт «Интригующие свойства нейронных сетей», в котором показали, что достаточно изменить в картинке всего несколько пикселей, и правильно определенное в первый раз изображение после небольшой оптимизации покажется классификатору незнакомым . Поддельные изображения ученые назвали адверсальными примерами.
Годом позже Джефф Клун из Университета Вайоминга в Ларами вместе со своим тогдашним студентом-аспирантом Ан Нгуеном обратили внимание на то, что нейронная сеть видит предметы даже там, где их нет. Можно создать изображения, которые будут неузнаваемы для людей, но с 99,9% вероятностью знакомыми для ИИ (например, королевский пингвин в узоре из волнистых линий)
Новый тип ошибки был представлен в 2018 году. Нгуен, который сейчас работает в Обернском университете, штат Алабама, узнал, что объект достаточно повернуть, чтобы ввести в заблуждение самые сильные классификаторы изображений. Скорее всего, это происходит, потому что предметы под другим ракурсом сильно отличаются от примеров, на которых сеть обучалась.
В 2019 Дэн Хендрикс, аспирант в области компьютерных наук Калифорнийского университета в Беркли, обнаружил, что даже неподдельные, сырые изображения могут заставить самые сильные нейронные сети делать непредсказуемые оплошности. Например, ИИ может определить гриб как крендель или стрекозу как крышку люка, потому что нейросеть фокусируется на цвете изображения, текстуре или заднем плане.
Идти за айфоном — попасть в полицейский участок
От ошибок, связанных с биометрической идентификацией, страдают не только россияне. В 2019 году американский студент Усман Бах подал в суд на Apple. В иске он утверждал, что система распознавания лиц в магазинах компании ложно связала его с преступником.
Незадолго до инцидента студент потерял водительское удостоверение. Он предположил, что нашедший документ злоумышленник воспользовался им, чтобы подтвердить личность при покупке в магазине. В этот момент система видеонаблюдения связала имя Баха с лицом другого человека, который позже совершил ещё несколько краж в разных городах и штатах страны. С такой версией согласился даже следователь из Нью-Йорка. Однако в других юрисдикциях Баха до сих пор обвиняют в кражах — даже несмотря на то, что у него есть алиби.
Баха арестовали в его доме в ноябре 2018 года. Однако в ордере полицейских была фотография другого человека. Подозреваемых объединял лишь чёрный цвет кожи, в остальном они были не похожи друг на друга.

Фото: canyalcin / Shutterstock
В иске Бах потребовал от Apple и её подрядчика по обеспечению безопасности магазинов Security Industry Specialists миллиард долларов. Он написал, что был вынужден ответить на многочисленные ложные обвинения, которые привели к сильному стрессу и лишениям в его жизни, а также к значительному ущербу его положительной репутации, для поддержания которой он приложил много усилий.
Миф 4. Все системы распознавания одинаковы
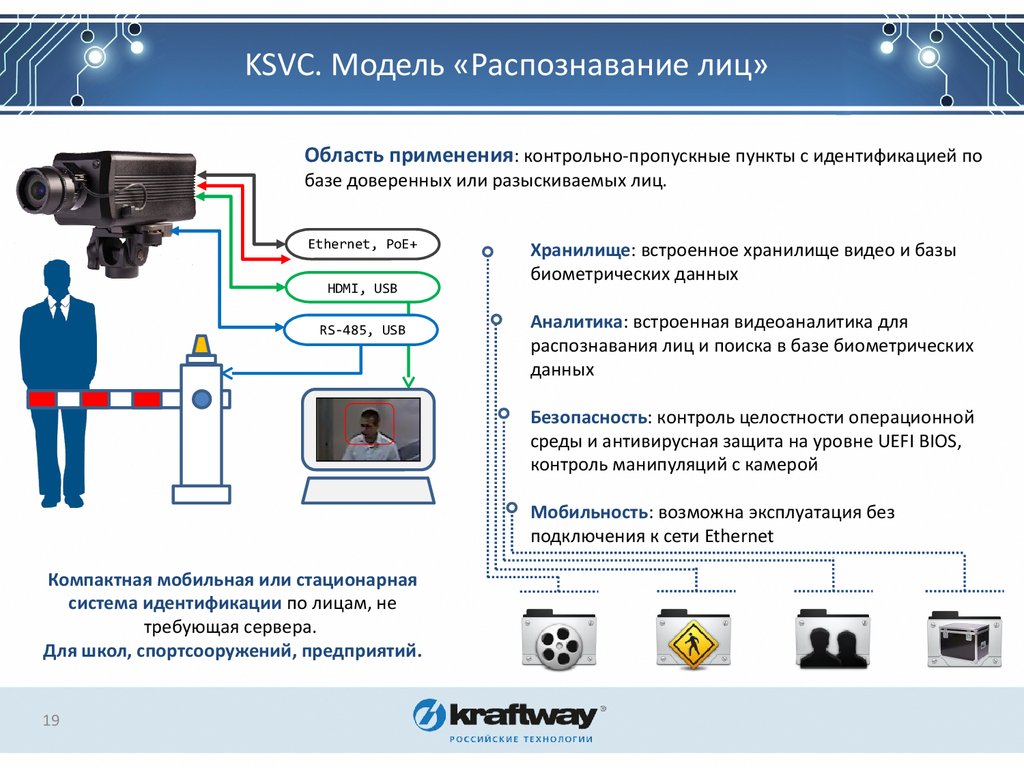
Схемы работы Face ID могут сильно отличаться друг от друга. Для примера обратимся снова к сравнению простого терминала распознавания и сложной системы для крупного предприятия. Различия в схеме их работы будут не столько в алгоритмах (теоретически они могут быть одинаковыми), сколько в их устройстве, в «железе».
Терминал — автономное устройство. В него, как правило, встроен дополнительный считыватель карт, управление входом/выходом, сама система распознавания. База образов также хранится непосредственно на нем. Решение о допуске или запрете на проход терминал принимает самостоятельно. Настройка может производиться на самом устройстве. Также возможна схема, при которой несколько терминалов объединены в единую систему с общей базой лиц. В таком случае решение принимает софт.
Распознавание лиц средствами системы видеонаблюдения всегда связано с сервером. Отсюда и дороговизна таких систем. Камера выступает просто инструментом получения исходной информации (снимка лица) для дальнейшей обработки на сервере.
При этом нельзя сказать что система на терминалах «неполноценная». Она имеет место быть и на крупных объектах. Все зависит от конкретной задачи и функций системы распознавания лиц.
Неопределенное будущее
Несмотря на примеры успешного применения биологических подходов в противодействии конфронтационным атакам, надежными их пока назвать нельзя. Быть может, очень скоро какой-нибудь другой исследователь опровергнет их эффективность. Подобное нередко случается в области конфронтационного машинного обучения.
Кроме того, не все считают биологические решения верным направлением.
«Нам не хватает знаний для создания биологических систем, имеющих гарантированную неуязвимость перед подобными атаками», — говорит Зико Колтер, специалист в области информатики из Университета Карнеги — Меллона. Колтер внес весомый вклад в разработку небиологических методов противодействия конфронтационным атакам.
Контекст
Вы можете заметить, что показатель ошибок людей в тестах вроде Switchboard довольно высок. Если бы вы общались с другом, и они не понимали 1 из 20 сказанных вами слов, вам было бы сложно общаться.
Одна из причин этого — оценка совершается независимо от контекста. В реальной жизни мы используем много других подсказок, чтобы понять, что говорит собеседник. Несколько примеров контекста, который используеют люди:
- Прошлые разговоры и тема обсуждения.
- Визуальные подсказки, например, выражения лица и движения губ.
- Знания о человеке, с которым мы общаемся.
Сейчас у распознавателя речи в Android есть доступ к вашему списку контактов, чтобы он мог распознавать имена ваших друзей. Голосовой поиск в картах использует геолокацию, чтобы сузить список потенциальных пунктов назначения. Точность ASR-систем возрастает с применением такого типа сигналов. Но мы только начала изучать, какой контекст мы можем включить и как мы можем это сделать.
Миф 6. Биометрическую базу могут взломать хакеры и использовать данные в своих целях
Мы констатируем повышенный риск для любых информационных систем со стороны хакерских атак. Это факт сегодняшнего дня. Биометрические данные, причисленные к персональным, всегда требуют повышенного внимания со стороны информационной безопасности.

Индустрия 4.0
Биометрия и диджитал-копии: как защитить себя и бизнес от кибермошенников
Для защиты таких данных сейчас используется распределенное хранение. Зашифрованный биометрический шаблон хранится на защищенных серверах в обезличенной форме отдельно от персональных данных. Выглядит он как некая математическая модель биометрических данных (лицо, отпечаток пальца, голос и так далее). Для обычного человека это представляет собой условно набор цифр. Восстановить из таких шаблонов образец голоса, изображение, отпечаток пальца без системы нельзя. А обезличенные сведения, даже с точки зрения внесенных в базу фотографий, не особенно интересны хакерам, поскольку для совершения каких-то мошеннических действий одного лишь изображения будет недостаточно.
«Для противодействия атакам биометрического спруфинга сегодня в банках используются такие механизмы подтверждения личности как liveness detection (дословно «проверка живости»). Это способность системы определять, является ли отпечаток пальца, лицо или другие биометрические данные реальным или поддельным. В качестве такой активной проверки биометрических данных, в частности, видеоизображения, человека могут попросить улыбнуться или повернуть голову. Система следит за естественностью движений пользователя, их соответствием полученному заданию и непрерывностью действий. При этом алгоритмы контролируют статику и динамику, что позволяет обнаружить взлом с использованием маски».
Как показывает практика, в большинстве случаев злоумышленники выбирают другие способы. Алгоритмы аутентификации пользователя мошенники стараются обходить с помощью социальной инженерии или уязвимостей в платежных приложениях.

Индустрия 4.0
Как защититься от кибермошенников — шесть основных схем обмана
Но нельзя исключать интерес злоумышленников к таким базам в части вывода системы из строя, что может стать элементом шантажа или вымогательства. Для защиты систем разработчики используют трансформацию биометрических параметров и криптографию. То есть в системе хранится только часть информации — защищенный эскиз.
«К примеру, при защите Единой биометрической системы в России, используется не один, а множество алгоритмов. Взлом даже одного займет у хакера много времени, сил и средств. А таких там десятки. К тому же они постоянно совершенствуются».
SimpleHTR эксперименты
SimpleHTR модель-это обучение, валидация и тестирование на двух различных датасетах. Для того чтобы запустить процесс обучения модели на наших собственных данных, были предприняты следующие шаги:
• Создан словарь слов файлов аннотаций
• Файл DataLoader для чтения и предварительного владения набором данных изображений и чтения файла аннотаций принадлежит изображениям
• Набор данных был разделен на два подмножества: 90% для обучения и 10% для проверки обученной модели. Для повышения точности и снижения частоты ошибок мы предлагаем следующие шаги: во-первых, увеличить набор данных, используя данные увеличение; во-вторых, добавьте больше информации CNN слоев и увеличение ввода размера; в-третьих, удалить шум на изображении и в скорописи стиле; В-четвертых, заменить ЛСТМ двусторонними ГРУ и, наконец, использование декодера передача маркера или слово поиска луча декодирование, чтобы ограничить выход в словарь слова.
Первый Набор Данных: Для обучения на собранных данных была обработана модель SimpleHTR, в которой есть 42 названия стран и городов с различными узорами почерка. Такие данные были увеличены в 10 раз. Были проведены два теста: с выравниванием курсивных слов и без выравнивания. После изучения были получены значения по валидации данных, представленных в Таблице ниже.
Алгоритм | выравнивание скорописи | нет выравнивания | ||
CER | WAR | CER | WAR | |
bestpath | 19.13 | 52.55 | 17.97 | 57.11 |
beamsearch | 18.99 | 53.33 | 17.73 | 58.33 |
wordbeamsearch | 16.38 | 73.55 | 15.78 | 75.11 |
Эта таблица показывает точность распознавания SimpleHTR для раличных методов декодирования (bestpath, beamsearch, wordbeamsearch). Декодирование наилучшего пути использует только выход NN и вычисляет оценку, принимая наиболее вероятный символ в каждой позиции. Поиск луча также использует только выход NN, но он использует больше данных из него и, следовательно, обеспечивает более детальный результат. Поиск луча с character-LM также забивает символьные последовательности, которые еще больше повышают исход.










Результаты обучения можно посмотреть на рисунке ниже:
Результаты эксперимента с использованием SimpleHTR (lr=0,01): точность модели.Результаты эксперимента с использованием SimpleHTR (lr=0,01): погрешность модели.
На рисунке ниже показано изображение с названием региона, которое было представлено на вход, а на другом рисунке мы видим узнаваемое слово ” Южно Казахстанская” с вероятностью 86 процентов.
Пример изображения с фразой ” Южно-Казахстанская” на русском языкеРезультат распознавания
Второй набор данных (HKR Dataset): Модель SimpleHTR показала в первом тесте набора данных 20,13% символьной ошибки (CER) и второго набора данных 1,55% CER. Мы также оценили модель SimpleHTR по каждому показателю точности символов(рисунок ниже). Частота ошибок в словах (WER) составил 58,97% для теста 1 и 11,09% для теста 2. Результат например TEST2 показывает что модель может распознавать слова которые существуют в обучающем наборе данных но имеют полностью различные стили почерка. Набор данных TEST1 показывает, что результат не является хорошим, когда модель распознает слова, которые не существуют в обучении и наборы данных проверки.
Следующий эксперимент проводился с моделью LineHTR, обученной на данных за 100 эпох. Эта модель продемонстрировала производительность со средним CAR 29,86% и 86,71% для наборов данных TEST1 и TEST2 соответственно (рисунок ниже). Здесь также наблюдается аналогичная тенденция переобучения обучающих данных.
Источники литературы
Object detection in 20 years: A Survey // Zhengxia Zou, Zhenwei Shi, Member, IEEE, Yuhong Guo, and Jieping Ye, Senior Member, IEEE.
Object detection with deep learning: A Review // Zhong-Qiu Zhao, Member, IEEE, Peng Zheng, Shou-Tao Xu, and Xindong Wu, Fellow, IEEE.
Shaharyar A., Zahra S. A comparative analysis of SIFT, SURF, KAZE, AKAZE, ORB, and BRISK // 2018 International Conference on Computing, Mathematics and Engineering technologies – iCoMET 2018.
Karami E., Prasad S., Shehata M. Image matching using SIFT, SURF, BRIEF and ORB: performance comparison for distorted images //arXiv preprint arXiv:1710.02726. – 2017.
Ethan Rublee, Vincent Rabaud, Kurt Konolige and Gary Bradski, “ORB: and efficient alternative to SIFT or SURF,” IEEE International Conference on Computer Vision, 2011.
Почему это важно?
Все основные подходы к распознаванию речи (Automatic Speech Recognition, далее ASR), включая современные end2end, рассчитаны на то, что на выходе будет только одна фраза.
ASR — это технология, преобразующая звук в текст и позволяющая людям использовать свой голос для общения с компьютерным интерфейсом. Как работает ASR? Системы распознавания речи делятся на несколько типов. Гибридные системы состоят из нескольких частей: акустическая модель предсказывает звуки языка (т.н. фонемы), далее с помощью словаря произношений и языковой модели получается текст. С развитием глубокого обучения и методов работы с большими данными стал возможен end2end (“сквозной”) подход — акустическая модель сразу предсказывает текст. |
Если говорят несколько человек одновременно, то для модели это незнакомый класс данных (out-of-domain), и она может выдавать неправильные результаты.
Один из подходов для решения таких проблем — добавить эти случаи в обучающую выборку, разметив то, что мы хотим получить на выходе. Пример: пользователь обращается к виртуальному ассистенту в комнате с работающим телевизором. Мы размечаем только обращение. К сожалению, такая разметка трудозатратнее и не всегда выходит качественной. При этом сложно набрать достаточный объём таких данных.
Есть более сложные случаи. Пример из реальной жизни:
Взрослый говорит: “Включи Босс-молокосос”. Ребёнок продолжает: “Два!”.
Нужно понять, что ожидаемое действие — включить “Босс-молокосос 2”. Получается, в таком подходе на модель ложится сразу несколько задач: 1) распознать речь всех говорящих; 2) понять, кто из них обращался к ассистенту; 3) если обращались несколько человек, то правильно скомпоновать запрос из их реплик. Скорее всего, у нас не хватит данных, чтобы научиться разбирать все случаи. С другой стороны, если бы мы знали результат распознавания по каждому говорящему, то получили бы больше контроля: определить финальный запрос можно с помощью более сильной NLP-системы или эвристик.
До этого момента мы говорили о работе виртуальных ассистентов Салют, но это не единственный сценарий использования ASR. Во внутренних продуктах мы также сталкиваемся с задачей, которую называем транскрибацией, когда нужно распознать длинную аудиозапись — например, подкаст. Такую задачу также хотят решать клиенты нашего внешнего API SmartSpeech. Типичный сценарий в таких записях — необходимость интерпретации перекрывающейся речи нескольких человек (высказывания накладываются друг на друга). Здесь не применимо понятие «основной запрос», нам нужна разбивка по фразам каждого говорящего — своеобразная «стенограмма» речи. Как выйти из этой ситуации? Доработать систему так, чтобы мы могли определять число говорящих и выдавать несколько транскрипций, по одной на каждого из них.
Шаг 3: Проверка формата и аннотаций
Этот шаг особенно важен для проектов, которые используют уже готовый датасет, найденный на просторах интернета
Важно проверить, что изображения в датасете находятся в том формате, с которым сможет работать выбранный фреймворк. Современные фреймворки работают с большим количеством разных форматов, однако до сих пор встречаются проблематичные форматы, например, jfif
Если изображения не будут находиться в нужном формате, процесс тренировки просто не сможет быть закончен, поэтому важно оказать этой, как может показаться, мелочи достаточно внимания. Необходимо также проверить аннотации и их формат
Изображения в датасете могут отвечать всем вышеперечисленным требованиям, но если аннотации не будут в том формате, с которым работает фреймворк и архитектура модели нейросети, то ничего работать не будет
Необходимо также проверить аннотации и их формат. Изображения в датасете могут отвечать всем вышеперечисленным требованиям, но если аннотации не будут в том формате, с которым работает фреймворк и архитектура модели нейросети, то ничего работать не будет.
В одних форматах аннотации, т.е. расположение bounding бокса на изображении, указывается в абсолютных значениях, в других – в относительных. Некоторые фреймворки, например YOLO, просят для каждого изображения cat.jpg приложить файл cat.txt с аннотацией, а другие, например TensorFlow, просит аннотации в формате .csv, некоторые просят приложить для тренировочного датасета один файл train.txt, который содержит все аннотации разом.
На этапе работы с датасетом важно знать с какой моделью будет вестись работа, ведь от этого зависит формат аннотаций и формат самих изображений
Результаты
Нам удалось построить систему, с помощью которой мы смогли получить относительное улучшение WER в 30% на срезе многоголосных записей. Кроме того, мы теперь можем транскрибировать речь каждого говорящего на двухголосных записях.
Как попробовать? Клиенты SmartSpeech API уже сейчас могут воспользоваться новым режимом распознавания, подробно об этом можно почитать в . Кроме того, в ближайшее время мы планируем улучшить с помощью этой технологии распознавание речи в наших умных устройствах Sber.
Ну и напоследок ещё один пример разделения сложной аудиозаписи с накладывающейся речью:
Исходная:
Первый канал:
Второй канал:
Почему системы распознавания лиц так часто ошибаются?
Всё большее число исследований показывает, что точность алгоритмов падает, когда им приходится идентифицировать лица людей другой расы. Например, если сеть обучена на распознавание белых, количество ошибок для темнокожих будет выше.
Ещё одним вызовом для разработчиков нейросистем стало повсеместное ношение масок во время пандемии. Первыми с проблемой столкнулись владельцы iPhone, которые привыкли, что телефон разблокируется, распознавая владельца по лицу. В Сети тогда появились многочисленные инструкции, как взломать гаджет, научив его узнавать человека в маске. Это побудило Apple решать проблему масок кардинально — её исправили в анонсированном к марту 2022 года обновлении.
Сравнить человека, ровно стоящего перед камерой, с его фотографией в базе данных сегодня очень просто, поясняет руководитель отдела по машинному обучению NtechLab Андрей Беляев. Но найти человека по фотографии, на которой его плохо видно, в профиль, в маске в базе с более чем миллионом человек, — это уже вызов.
Фото: Shawn Goldberg / Shutterstock
Ещё один аспект, который влияет на точность, — данные, на основе которых обучаются нейросети. Все компании пользуются практически одинаковым набором фреймворков и библиотек, на которых они разрабатывают свои системы и обучают нейросети. Однако различия всё-таки есть — в самих данных. Для обучения нейросети нужно много данных, а данные «локального» производства всегда ищутся лучше.
«Сетки, обученные китайской компанией, скорее всего, будут лучше работать на жителях Китая, чем сетки, обученные в Европе. И наоборот — европейские нейросети будут лучше работать в Европе», — поясняет Беляев в разговоре со Skillbox Media.
Тем не менее тренд по борьбе с дискриминацией укрепляется. Разработчики больше внимания уделяют тому, чтобы алгоритмы одинаково хорошо работали на представителях разных этнических групп и чтобы точность не зависела от страны, в которой находится производитель. Для этого перед выпуском алгоритма видеоаналитики на рынок разработчики проводят набор тестов для каждой отдельной этнической группы и проверяют, чтобы точность во всех случаях была одинаковой.
Затормозить этот процесс могут разве что финансовые возможности компаний, которые внедряют решения на основе Face ID. Операционный директор финтех-платформы «Фаст Ривер» Ксения Артемьева говорит, что высокоточные системы требуют и дорогостоящего оборудования. Например, распознавание 3D‑изображений более точное, чем распознавание 2D, но требует наличия мощного 3D-сканера.
«Сканеры Face ID в телефонах сейчас можно обмануть высокоточным 3D‑отпечатком лица, которое можно напечатать на принтере», — сказала Ксения Артемьева Skillbox Media.
Она также напоминает, что сегодня возможен анализ по структуре кожи и сетчатки глаз, но для этого необходимы высокоточные камеры с высоким разрешением. Существует даже анализ теплового слепка лица. Если комбинировать все доступные инструменты, это потребует больше вычислительных мощностей и сложного оборудования, но позволит снизить количество ошибок для минимума, говорит Артемьева.










Находим лицо в кадре
Перед тем как алгоритм приступит к распознаванию, ему нужно найти лицо на картинке. Для этого он использует метод Виолы — Джонса и специальные чёрно-белые прямоугольники (примитивы Хаара), которые выглядят примерно так:

С помощью этих прямоугольников алгоритм пытается найти на картинке похожие переходы между светлыми и тёмными областями. Если в одном месте программа находит много таких совпадений, то, скорее всего, это лицо человека. Например, вот как с помощью этих примитивов алгоритм находит нос и глаза:
Все примитивы специально подобраны так, чтобы с их помощью можно было найти границы лица и отсечь всё остальное. Поэтому, как только алгоритм находит место скопления таких совпадений, он для проверки сравнивает там остальные прямоугольники:

Если их набирается достаточное количество — это точно лицо. Обычно алгоритмы поиска лиц для контроля обводят рамкой найденную область — она помогает разработчикам понять, всё ли в порядке с логикой программы:

Когда есть алгоритм и достаточно быстрый процессор, находить лица — дело техники. Такие алгоритмы известны, их много, они работают даже на маломощных Raspberry Pi
Что с датасетами?
Сначала пара слов о требованиях к датасету. Напомню, что датасет – это некоторая случайная выборка из генеральной совокупности всех примеров. На языке математики от такой совокупности требуется равномерное распределение по генеральной совокупности. И, конечно, необходимо следить за снижением размерности задачи машинного обучения и нормализацией данных. Но, как говорили классики, «есть один нюанс». Получить представление о генеральной совокупности примеров непросто и требует знания бизнес-специфики и задач пользователей. И эта задача находится на пересечении компетенции датасайентиста и бизнес-аналитика. По-хорошему, им обоим надо сильно подружиться (поработать вместе), чтобы сформировать полное представление о генеральной совокупности.
В нашем случае мы совместно с бизнес-аналитиком провели больше двух десятков интервью с конечными пользователями, чтобы понять, в каких сценариях могут возникать задачи перехвата оттиска печатей, какими могут быть эти оттиски и как часто подвергаться тем или иным искажениям. Например, оттиски печатей могут находиться на:
Программно-конвертируемых изображениях,
Скриншотах экранов, сделанных на всевозможных типах сканеров,
Сфотографированных оригиналах документов,
Сфотографированных фотографиях и копиях документов,
Снимках с веб-камеры.
Помимо этого, изображение может быть искажено по различным причинам:
Поворот, растяжение, сжатие,
Сворачивание исходного документа,
Смятие исходного документа,
Частичное отображение искомого объекта,
Размытие и смазывание,
Наложение на текст, другие печати, водяные знаки.
Сами печати могут относиться к разным степеням коммерческой значимости. Эти факторы и их распределение должны формировать сбалансированную равномерно распределенную выборку из генеральной совокупности – датасет.
Алгоритмы, алгоритмы, а я маленький такой
За последние десять лет зоопарк решений по детектированию объектов настолько вырос, что нам пришлось проводить отдельный НИР по выявлению вариантов подходящих моделей.
Выбор стоял между наиболее актуальными на сегодняшний день нейронными сетями и давно зарекомендовавшими себя вариациями SIFT-алгоритма. А с учетом того, что последний не так давно просрочил свой патент, стало возможным его использовать в коммерческих решениях свободно.
Иллюстрация 7: История развития алгоритмов SIFT и CNN
Изучили наиболее известные статьи по сравнению двух подходов. Наиболее содержательными видятся статьи, проводящие сравнение двух подходов:
Общий вывод исследователей следующий. Алгоритмы SIFT-based хорошо справляются с поиском очень похожих дубликатов и менее пригодны для детектирования более широких классов объектов.
Тогда как сверточные нейронные сети, напротив, лучше справляются с обнаружением похожих, не обязательно идентичных объектов. При этом начинают чаще путаться при задаче отделения дубликатов от просто похожих изображений.
Алгоритм | Хорошо | Плохо |
SIFT | Задачи идентификации, поиска дубликатов. Легко встроить в продукт. Быстрый | Плохо обобщает объекты. Плохо справляется с нелинейными искажениями |
CNN | Задачи классификации, поиска объектов определенного типа. Очень хорошо ищет похожие объекты, обобщает | Потребляет много ресурсов. Требует большого датасета для обучения. Требует настройки |
Таблица 3: анализ преимуществ и недостатков SIFT и CNN
Для прототипа решения обеих наших задач были выбраны несколько моделей из Tensorflow Object Detection, реализация SIFT в OpenCV, а также его аналог ORB.
А теперь расскажем про отдельные интересные особенности решения обеих задач.
Комплексное решение
Определившись с алгоритмом сопоставления заданной печати с детектированным объектом, необходимо было найти способ выделять данную область с печатью в отдельное изображение. Это позволило бы значительно улучшить точность алгоритма сопоставления, а также сократить время распознавания, поскольку в данной операции участвовало бы не все изображение документа, а лишь конкретные его участки, там, где обнаружена печать (штамп).
Для решения этой задачи был написан скрипт на языке Python. После того, как загруженная в оперативную память компьютера модель-детектор (наша обученная модель) выполняет свою часть работы, связанную с обнаружением на входных изображениях документов участков с печатями (штампами), выполняется операция вырезания данных участков. Далее каждое вырезанное изображение поочередно сопоставляется с заданной печатью (образцом).
Результаты работы скрипта выглядят следующим образом:
Иллюстрация 18: Распознавание конкретной печати из заранее детектированных всех печатей
Таким образом, была реализована программа, объединившая в себе два алгоритма, – детектирование объектов и сопоставление изображений. В качестве альтернативы возможно применение другой обученной модели-детектора либо замена алгоритма SIFT на BRIEF или ORB. По итогам тестирования получившееся решение показало достаточно хорошие результаты в распознавании конкретных печатей на документах.




Классификация
Классификатор – алгоритм, который отвечает на вопрос, есть ли заданный нами объект на изображении (не более того). Допустим, у нас есть несколько объектов, о существовании которых на изображениях мы хотели бы знать. Пусть это будут печать, подпись и печатный текст. У нас есть несколько изображений:
Иллюстрация 4: Варианты объектов (печать, подпись и печатный текст)
Что получится на выходе? Обычно для каждого изображения это словарь следующего вида:
{
объект_1: вероятность_нахождения_на_изображении_объекта_1,
объект_2: вероятность_нахождения_на_изображении
… ,
объект_n: вероятность_нахождения_на_изображении
}
Но просто вероятность не дает нам ответа «ДА, НА ЭТОМ ИЗОБРАЖЕНИИ ЕСТЬ ЭТОТ ОБЪЕКТ» или «НЕТ, НА ЭТОМ ИЗОБРАЖЕНИИ НЕТ ЭТОГО ОБЪЕКТА». Для этого необходимо использовать порог – специальное значение, вероятность выше которого означала бы положительный ответ, а ниже – отрицательный.
Что получится в таком случае для изображений выше? Примерно следующее:
Таблица 2: порог вероятности для положительного и отрицательного результата распознавания
2 главные уязвимости биометрических Big Data систем на базе Machine Learning
Прежде всего отметим, что для биометрических систем характерны те же факторы возникновения рисков, как и для любого Big Data проекта. В частности, здесь мы анализировали, почему случаются утечки данных: в основном, виноваты люди (сторонние хакеры или внутренние пользователи), инфраструктурные проблемы, уязвимости программного обеспечения или сторонние сервисы. Однако, помимо этих причин, биометрии свойственны специфические проблемы, непосредственно связанные с самими алгоритмами распознавания личности на базе методов машинного обучения. Поэтому их называют естественными ограничениями биометрических методов идентификации. При этом могут возникнуть ошибки 1-го и 2-го родов по матрице ошибок (confusion matrix) :
- ложное соответствие из-за вторжения злоумышленника, который сумел обмануть ML-алгоритмы распознавания, выдав себя за другого пользователя – вариант False Positive (ложноположительное решение, FP), ошибка 1-го рода;
- ложное несоответствие и отказ в обслуживании, когда ML-модель не смогла распознать легитимного пользователя, не найдя в базе подходящего цифрового шаблона для представленных биометрических персональных данных (БПД) – вариант False Negative (ложноотрицательное решение, FN), ошибка 2-го рода.
Ошибка 2-го рода, в основном, связана с качеством алгоритмов распознавания и/или качеством входных данных. А ошибки 1-го рода, как правило, возникают вследствие атаки подделки, когда фальсифицируется биометрическая черта, используемая в ML-алгоритмах. Например, искусственный палец с нужными отпечатками, трехмерная маска лица или даже реальная часть тела легитимного пользователя, отрезанная от него . Именно такой инцидент произошел с владельцем премиального автомобиля в Малайзии в 2005 году, которого покалечили преступники при попытке угнать его машину . Впрочем, злоумышленники успешно применяют и менее травматичные способы изготовления поддельных биометрических носителей. В частности, хакеры имитируют нужные отпечатки пальцев с помощью силиконовых пленок, графитового порошка и суперклея, а фото лица – гипсовыми копиями головы и масками. Такие методы позволяют обмануть простые биометрические системы идентификации в смартфонах с не слишком сложными ML-алгоритмами и/или не самыми чувствительными датчиками .
На самом деле оба варианта ложных срабатываний весьма нежелательны, т.к. влекут за собой неправомерные действия с информацией (в случае FP) или недовольство пользователя (в случае FN), что приводит к репутационным потерям и увеличивает вероятность оттока клиента (Churn Rate).

Атака подделки с помощью искусственного пальца
Попробуем подвести итоги и сделать выводы
Ну вот! Мы объединили два алгоритма – нейронные сверточные сети CNN и SIFT и получили прототип, подходящий для коммерческого решения. Но не тут-то было. Для того, чтобы он стал рабочим решением, необходимо было защитить его перед владельцем продукта и архитекторами и еще не раз подтвердить обозначенные вначале бизнес-метрики. Во время обсуждений с архитекторами и разработчиками были обнаружены проблемы в архитектуре и библиотеках, которые несколько раз корректировали исходную алгоритмическую схему, что снова меняло ML-метрики. Так было принято решение использовать в продукте два режима (точности и полноты), поскольку разным бизнес-пользователям могут быть важны несбалансированные точность и полнота.
На создание бизнес-успешно работающего прототипа у нас ушло суммарно 3 месяца работы трех человек с учетом бизнес-аналитика. Два месяца на задачу распознавания любой печати и один месяц на задачу распознавания заданной печати.
Много это или мало, что думаете?)





